はじめに
前回のコラムでは音声から感情を検出する仕組みのアウトラインを解説しました。
今回と次回のコラムでは、前回十分に説明しきれなかった項目について少し詳しく解説します。
特に、人工知能(AI:Artificial Intelligence)を使った感情検出と、AIを使わない感情検出との違いについて説明します。
結論から言いますと、当社の感情解析ソリューションALICeで採用している感情検出はAIを使わないで行う方式です。
但し、検出した感情データを用いてどのようにビジネス場面で使うのかのアドバイスにはAIを利用いています。
1. コンピューターによる感情解析手法の種類
音声から話し手の感情を推定するには大別して言語情報分析型と音響的特徴分析型の2つの方法があります。
前者はAIテクノロジーを応用したもので、IBM社が提供するWatson Tone Analyzerや、マイクロソフト社が提供するAzureのEmotion APIがこれに相当します。
後者はAIを使わずに音声信号の音響的特徴(音量、ピッチ、リズムなど)を分析し、経験データから感情を推定するものです。
当社が提携しているイスラエルのEmotionLogic社が提供している階層別音声解析LVA(Layered Voice Analysis)は後者になります。
では、これらの2種類の手法について詳しく解説します。
2.AIを用いた感情解析(言語情報分析型)
この方式は、感情解析に関しては比較的経験の浅い大手企業(IBMやマイクロソフト、Googleなど)が採用している方式です。
一般的に、この方式を採用している企業はAIテクノロジー全般に多大な投資をしており、投資に対する収益を確保するために、AIをマーケティング、ヘルスケア、コールセンター、製造支援、セキュリティ、金融、など、あらゆる分野に適応しています。
これらの適応にあたり、画像認識、音声認識、言語処理、機械学習、深層学習、などいろいろな汎用的なテクノロジーを駆使しています。
感情解析はこれらの汎用テクノロジーを組み合わせて実現します。
多くの場合、受信した音声を、一旦、Speech To Text(音声から文字に変換するソフト)を用いて文字情報(テキスト)に変換し、これを自然言語処理(NLP:Natural Language Processing)ソフトを用いて、テキストの中から感情を読み取ろうとする方法です。
感情は過去のソーシャル・メディアの投稿、反応、レビューなどで使用される言葉との比較を用いて同定されることが一般的です。 この方法は次の処理プロセスにより行われます。
言語情報分析型の感情解析プロセス
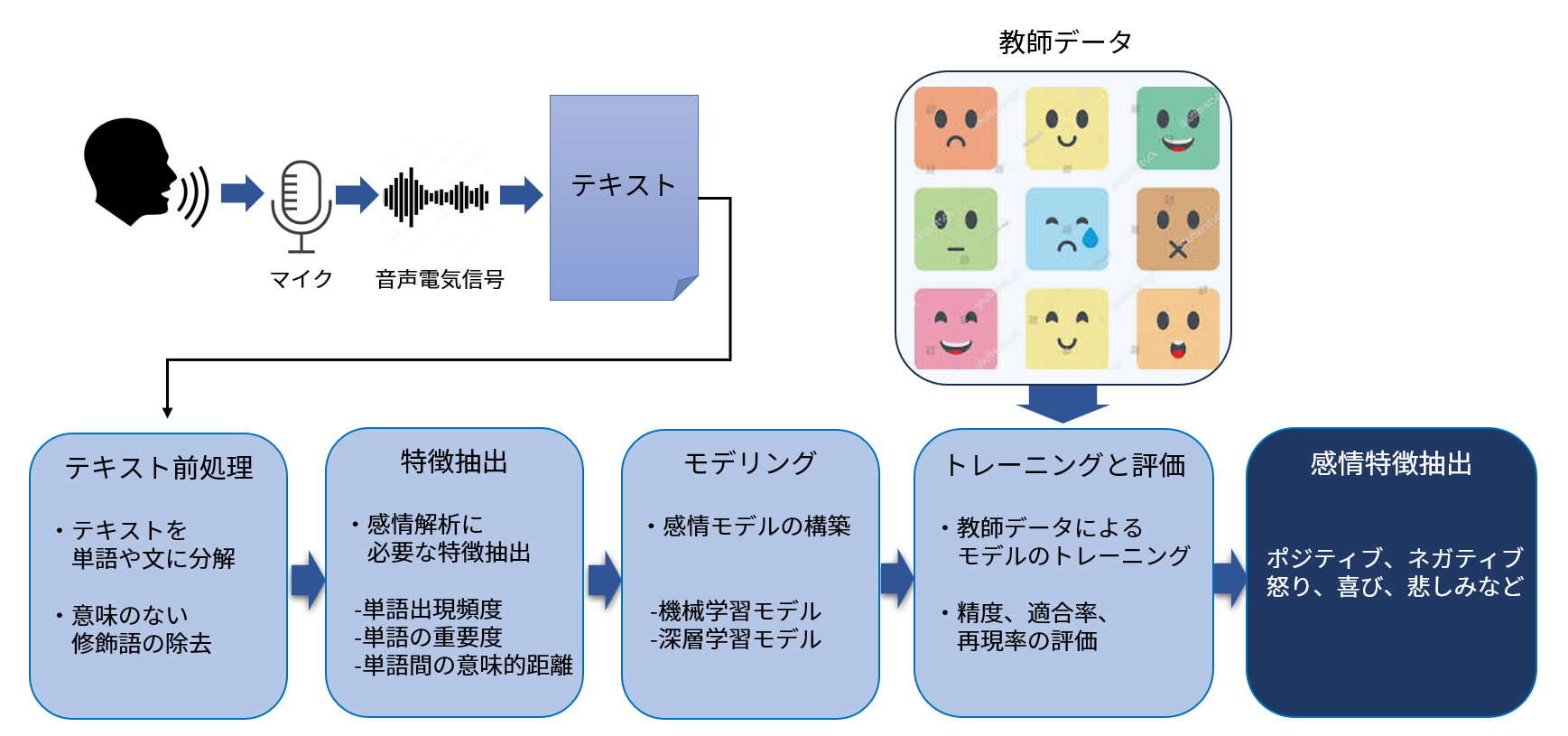
(1) テキスト化
まず、音声をマイクで聞き取り、それをSpeech To Textのソフトを使ってテキスト化します。
音声の音響的な特徴は使わず、音声に含まれる言語情報のみを使って感情を推定することになります。
(2) テキスト前処理
テキストから感情解析に必要なデータ特徴を抽出します。
単語の頻出頻度、単語の重要度、複数の単語間の意味的な距離(関係性の大小)などが抽出されます。
(3) モデリング
このプロセスはAIに特有な部分ですが、機械学習(ML:Machine Learning)及びその一分野である深層学習(DL:Deep Learning)を使った自然言語処理(NLP:Natural Language Processing)を用いてモデル化します。
すなわち、入力データの中から感情の特徴を自動的に抽出し、個々の特徴データ相互間の相関性などの法則性を見つけ出し(モデル化)、新しいデータが与えられたときにそのデータの感情特徴を抽出できるようにすることです。
(4) トレーニングと評価
感情の特徴をテキストから割り出すには、事前にSNSやスピーチなどでの発言やそのレスポンス、感想などの情報を大量に教師データとして読み込ませ、モデルをトレーニングします。
例えば怒りに任せて書いた文章の特徴を覚えこませ、入力したテキストに怒りの感情が含まれているかどうかを判断させるように訓練します。
トレーニングを施したモデルにテキストを入力し、その中にどのような感情がどの程度含まれるのかを出力させて検証評価します。
(5) 感情特徴抽出
最後に、モデルから入力したテキストに含まれる感情の特徴(ポジティブ、ネガティブ、怒り、喜び、悲しみなど)を定量的に出力します。
これら一連のプロセスで重要なことは大量の教師データを読み込ませることです。
深層学習は大量のデータから特徴とその規則性を自動的に抽出し、それに基づき感情解析の対象となる入力テキストに含まれる感情の特徴を人間の手を借りないで判断します。
人間の手を介さずに判断することができるので人口知能(AI)と言われます。
言語情報分析型の課題
前回のコラムで音声には、①言語情報、②意図的な感情に関する情報、③不随意感情に関する情報の3種類が含まれていることを説明しました。
このうち、我々が本当に知りたい感情に関する情報は③の不随意感情です。
しかし、音声を一旦①の言語情報にしてしまうと、音声の中に含まれる②や③の情報はほとんど消え去ってしまいます。
教師データを大量に読み込ませることにより①から②を推定させることはある程度できますが、①から③を推定させることは困難です。
従って、俳優が感情を模倣して出した声から模倣感情を推測させることは出来ても、非言語的情報である不随意感情(真の感情)を推定することは、言語情報分析型の感情解析手法では相当の無理があることがお分かりいただけると思います。
3.AIを使わない感情解析(音響的特徴解析型)
当社が採用している方式です。音声は音であり、話す人毎にその声には音響的な特徴があります。
音響的特徴には次のような項目があります。
① ピッチ(声の周波数に関連するパラメーター)
・声帯の出す音の周波数と帯域
・声道の共鳴周波数
・音声波形周期性の不安定度(ジッターと言います)
② 声量(声の大きさに関連するパラメーター)
・声の音量(エネルギー)レベル
・音量の不安定度(シマーと言います)
③ 音声波形の形(声の質)
・プラトー(波形が平たんな部分)の出現回数と頻度
・ソーン(急峻な刺のような音声波形)の出現回数と頻度
・周波数の分布
④ 会話速度(音声の時間的なパラメーター)
・話者波形ピーク出現頻度
・単位時間中の連続有音時間の割合
・会話中で声が実際に出ている時間と出ていない時間
感情と音響特性との間には相関関係があるということが分かっています。
この分野ではベルリン工科大学のM Kienast博士と W F. Sendlmeier博士の研究が有名です。
「感情的なスピーチにおけるスペクトルと時間的変化の音響分析」
ミリアム・キエナストとウォルター・F・センドルマイヤー著
2000 年にベルファストで開催されたスピーチと感情に関する ISCA ワークショップ (ITRW) の議事録に掲載
この研究によれば、上記の音響特性測定値から計算されたスペクトル平衡と言われる音響特性の値が、怒り、幸福、恐怖の感情の時には比較的大きく、退屈と悲しみの場合には低いことが実験的に明らかになっています。
この結果を用いてオープンソフトの音声感情解析ソフトOpenVokaturiがリリースされており、研究者の間では重宝がられています。
但し、この実験は疑似的に感情を模倣した俳優の声を測定して結果を導き出しているために、「真の感情」が必要な警察捜査などの機微な感情推移をOpenVokaturiで扱うのは無理があるでしょう。
実際のところ、ほとんどの感情解析ソフトのベンダーは、声の音響特性から感情を導き出すアルゴリズムは企業秘密として公開されていません。
当社の提携先であるイスラエルのEmotionLogic社の場合にも詳細は公開されていません。
同社はこのアルゴリズムをLVA(階層別音声解析Layered Voice Analysis)と名付けています。
特許やLVAに関するホワイトペーパーなどの記述から概ね次のプロセスで感情を推定しています。
音響的特徴解析型のプロセス
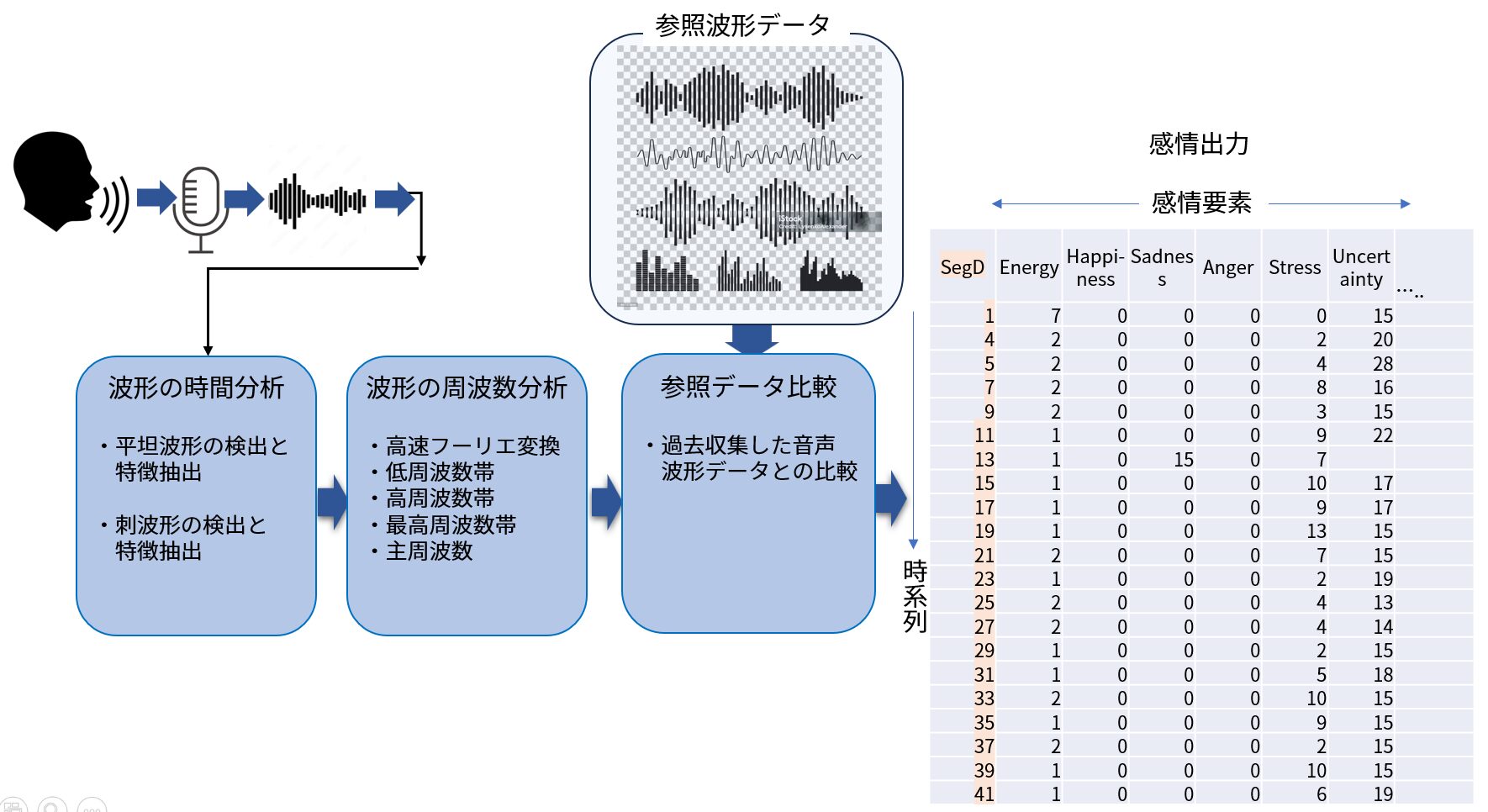
この方式は、入力された音声波形から一旦テキストに変換することなく、波形の特性そのものから話者の感情を推定するものです。
波形の分析は主に時間分析と周波数分析を用いて行われます。
(1) 波形の時間分析
入力音声波形(横軸は時間、縦軸は音の強度)を眺めると、同じ強度が時間的に続く平坦な部分(平坦波形)と短時間で強度が急峻に変化する部分(刺波形)があることに気が付きます。
この出現回数、頻度、平均時間長、及び平均からの偏り(偏差)から波形の特徴抽出を行います。
EmotionLogic社はこれらの値がさまざまな感情要素に関係していることを実際の音声データを用いて導き出しました。
例えば人間がストレス状態に置かれると平坦部分の偏差が大きくなり、平坦部分が次々と大きくなったり小さくなったりすることを繰り返します。
興奮状態になると棘の部分の出現回数が多くなります。
感情と音声波形に関するこれらの関係性から、いろいろな感情に対する計算式を導き出して話者の感情状態を数値で出力します。
残念ながらこれらの計算式は企業秘密として公開されていません。
(2) 波形の周波数分析
次に、2秒程度の長さの入力波形を高速フーリエ変換と言う数学的アルゴリズムを用いて周波数成分に変換します。
この波形を周波数スペクトラムと言い、横軸は周波数、縦軸は成分強度です。
これは一般的に低周波数帯域(0から2,000ヘルツ程度)、高周波帯域(4,000から10,000ヘルツ程度)、最高周波帯域(10,000ヘルツ領域)に分けられます。
また平均周波数(主周波数と言う)も測定可能です。
周波数分布から波形の特徴抽出を行います。
EmotionLogic社が収集した音声サンプルの実測により周波数と感情には次のような関係があることがわかりました。
① 低い周波数帯
話者の思慮・思考の程度、論理的な感情の程度に関係します。
この周波数帯が多い会話は深く思慮しながら話しており、場合によっては論理矛盾を感じながら話していることを示しています。
② 高い周波数帯
話者の情緒や、感情的に話しているかどうかに関係します。
この領域の周波数が多い場合は話者が感情的に話していることを示します。
また愛情をもって話しているときはこの領域の周波数が多くなります。
③ 最も高い周波数領域
この領域は躊躇の度合いに関係しています。
ここの周波数が多い場合は躊躇の感情の度合いが高いと推定されます。
④ 主周波数
会話の中の最も大きな周波数成分が話者の周波数帯域のどこに位置するのかを示す指標です。
この値が大きいと話者が高い関心を持った話題を話している状態を示します。
(3) 参照データとの比較
時間分析と周波数分析に引き続き、過去からEmotionLogic社が言語、性別、民族、年代の人々の、いろいろな状況における音声サンプルデータと照合します。 これらのデータは一つ一つEmotionLogic社の研究者や協力者により、どのような感情要素が含まれるかを同定していったもので、コンピューターが深層学習アルゴリズムや自然言語処理で自動的に、すなわちAIを用いて感情を同定したものではありません。
時間分析と周波数分析に加え、これらの収集データと参照することにより、最終的に入力音声波形にどのような感情要素がどの程度含まれているかを計算します。
(4) 感情の出力
前回のコラムで解説しましたが、人間の感情は単純なものではありません。
ストレス、不安、怒り、喜びなどさまざまな感情が同時に沸き上がります。
嬉しいけど憎い、怖いけど楽しいなど一見矛盾した感情も同時に脳内に存在します。
従って、単純に人間の感情状態を「怒り」、「喜び」、「ストレス」など単一の状態で表現することは出来ません。
そこで当社のALICeでは提携元のEmotionLogic社の感情表現方法に従って感情要素という概念を採用しています。
これは人間の感情状態を感情エネルギーの程度、喜びの程度、悲しみの程度、怒りの程度などの感情要素に分解し、その人が抱いている感情要素の程度を数値で表す方法です。
感情状態は時系列的に変化しますから、約2秒毎の感情要素の値を、時刻を列に、感情要素を行にした行列形式で出力します。
感情の種類は数十あり、使用目的により異なります。
LVAには、各音声セグメントから150以上のパラメーターを抽出する独自の信号処理アルゴリズムで構成される3つの基本式があります。
感情解析の目的に応じて、感情要素の出力方法は変わります。 その出力例を示します。
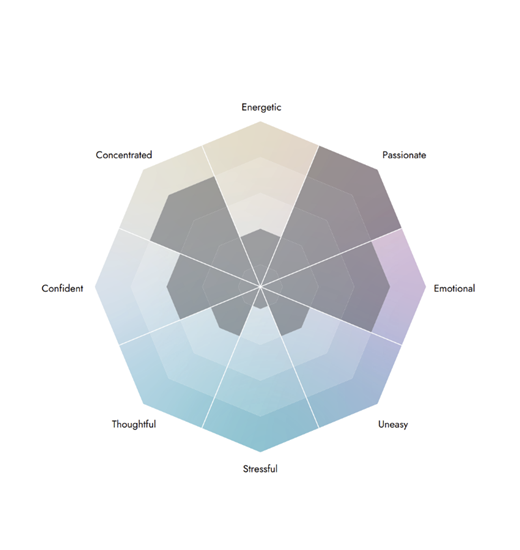
感情ダイヤモンド
話者の全般的な感情状態を示すもので、「エネルギー」「熱意」「情緒」「不安」「ストレス」「思慮」「自信」「集中」を感情ダイヤモンドとして簡潔に表現したものです。
動画で数秒毎に形が変化し、話者の感情変化の様子がわかります。
CSV(エクセル)表示
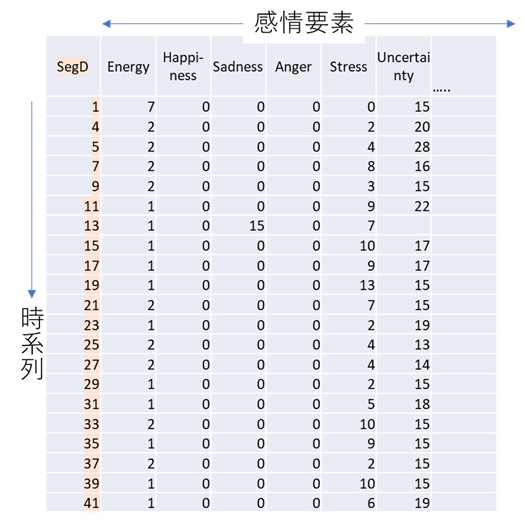
これは複数の感情要素の値を時系列(デフォルト2秒毎)に表した表現方法です。
表現する感情要素の種類は、コールセンターソリューション、メンタルヘルスソリューション、捜査支援ソリューションなどのソリューション毎に異なります。
おわりに
今回のコラムでは、AIによる感情解析と非AI感情解析の内容を紹介しました。
当社が採用している方式は、話者の感情の同定には非AI方式です。
感情要素一つ一つに人間が介在したデータを用いて話者の感情状態を判定しています。
従って、コンピューターが勝手に感情を判断する仕組みとは大きく異なることをご理解ください。

